1.subprocess模块
2.loggin模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical()5个级别,下面我们看一下怎么用。
import logginglogging.warning("user [alex] attempted wrong password more than 3 times")logging.critical("server is down") 结果:
WARNING:root:user [alex] attempted wrong password more than 3 timesCRITICAL:root:server is down
如果想把日志写进文件里:
import logginglogging.basicConfig(filename='example.log',level=logging.INFO)logging.debug('This message should go to the log file')logging.info('So should this')logging.warning('And this, too') level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里。
自定义日志格式
加上时间输出:
import logginglogging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')logging.warning('is when this event was logged.')#输出12/12/2010 11:46:36 AM is when this event was logged. 除了加时间,还可以自定义一大堆格式,下表就是所有支持的格式
| %(name)s | Logger的名字 |
|---|---|
| %(levelno)s | 数字形式的日志级别 |
| %(levelname)s | 文本形式的日志级别 |
| %(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 |
| %(filename)s | 调用日志输出函数的模块的文件名 |
| %(module)s | 调用日志输出函数的模块名 |
| %(funcName)s | 调用日志输出函数的函数名 |
| %(lineno)d | 调用日志输出函数的语句所在的代码行 |
| %(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 |
| %(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数 |
| %(asctime)s | 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
| %(thread)d | 线程ID。可能没有 |
| %(threadName)s | 线程名。可能没有 |
| %(process)d | 进程ID。可能没有 |
| %(message)s | 用户输出的消息 |
日志同时输出到屏幕和文件
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
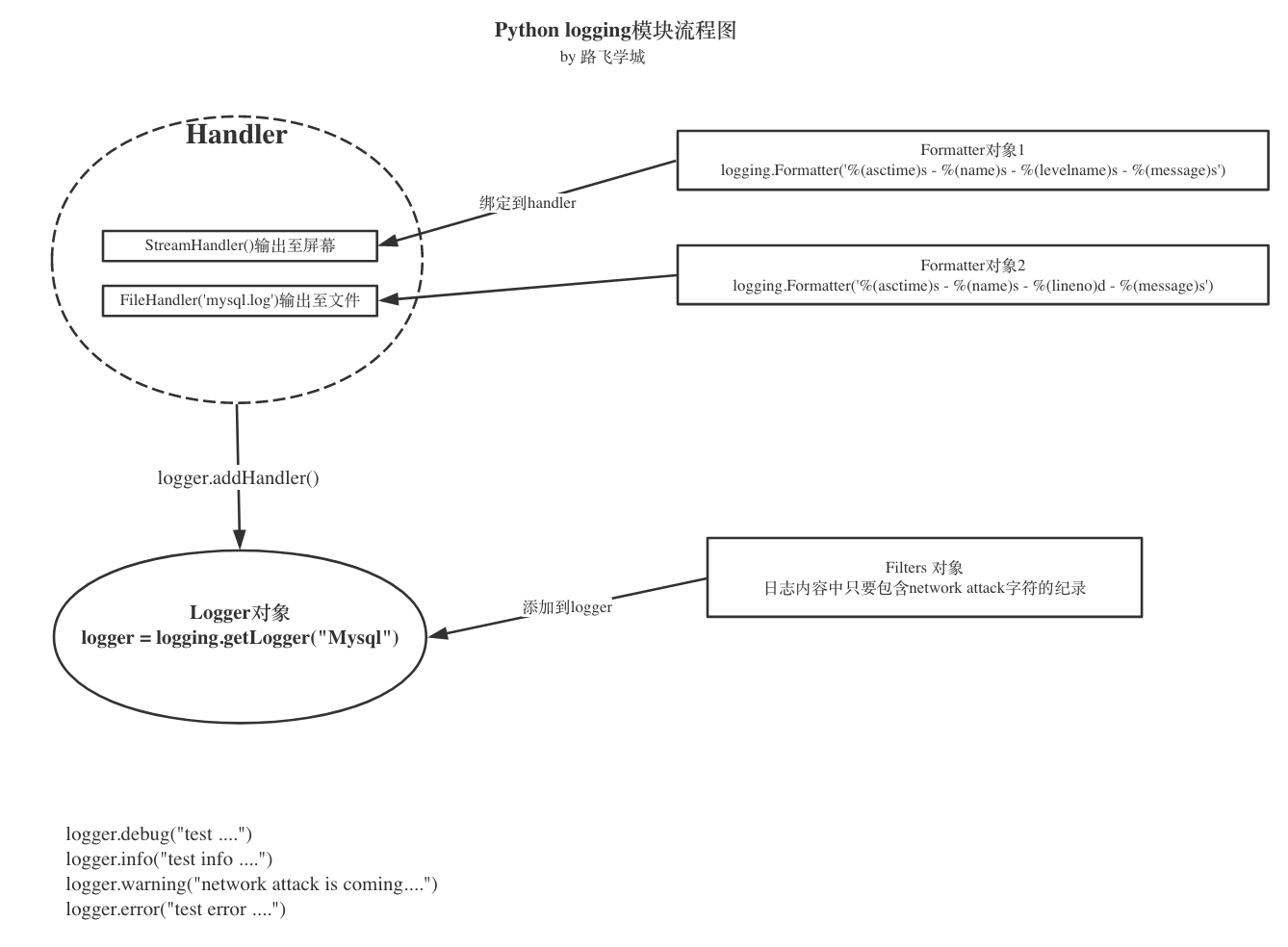
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。
他们之间的关系是这样的:
每个组件的主要功能:
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
还可以绑定handler和filters:
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filterLogger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Handler可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略Handler.setFormatter():给这个handler选择一个格式Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1.logging.StreamHandler 使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
2.logging.FileHandler 和StreamHandler 类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件
3.logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
- maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
- backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4.logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
- S 秒
- M 分
- H 小时
- D 天
- W 每星期(interval==0时代表星期一)
- midnight 每天凌晨
formatter
日志的formatter是个独立的组件,可以跟handler组合
fh = logging.FileHandler("access.log")formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')fh.setFormatter(formatter) #把formmater绑定到fh上 filter
如果你想对日志内容进行过滤,就可自定义一个filter
class IgnoreBackupLogFilter(logging.Filter): """忽略带db backup 的日志""" def filter(self, record): #固定写法 return "db backup" not in record.getMessage()
注意filter函数会返加True or False,logger根据此值决定是否输出此日志
然后把这个filter添加到logger中
logger.addFilter(IgnoreBackupLogFilter())
下面的日志就会把符合filter条件的过滤掉
logger.debug("test ....")logger.info("test info ....")logger.warning("start to run db backup job ....")logger.error("test error ....") 一个同时输出到屏幕、文件、带filter的完成例子
import loggingclass IgnoreBackupLogFilter(logging.Filter): """忽略带db backup 的日志""" def filter(self, record): #固定写法 return "db backup" not in record.getMessage()#console handlerch = logging.StreamHandler()ch.setLevel(logging.INFO)#file handlerfh = logging.FileHandler('mysql.log')#fh.setLevel(logging.WARNING)#formatterformatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')#bind formatter to chch.setFormatter(formatter)fh.setFormatter(formatter)logger = logging.getLogger("Mysql")logger.setLevel(logging.DEBUG) #logger 优先级高于其它输出途径的#add handler to logger instancelogger.addHandler(ch)logger.addHandler(fh)#add filterlogger.addFilter(IgnoreBackupLogFilter())logger.debug("test ....")logger.info("test info ....")logger.warning("start to run db backup job ....")logger.error("test error ....") 文件自动截断例子
import loggingfrom logging import handlerslogger = logging.getLogger(__name__)log_file = "timelog.log"#fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3)formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')fh.setFormatter(formatter)logger.addHandler(fh)logger.warning("test1")logger.warning("test12")logger.warning("test13")logger.warning("test14") 3.re模块——正则表达式
常用的表达式规则
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1'*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa''+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次'{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb''{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45''\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^'\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9'\D' 匹配非数字'\w' 匹配[A-Za-z0-9]'\W' 匹配非[A-Za-z0-9]'\s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t''(?P ...)' 分组匹配 例re.search("(?P [0-9]{4})(?P [0-9]{2})(?P [0-9]{4})","371481199306143242").groupdict("city") # 身份证号分割 结果{ 'province': '3714', 'city': '81', 'birthday': '1993'}
re的匹配语法有以下几种
- re.match 从头开始匹配,只匹配第一个字符,匹配不到返回None ,若想拿到匹配的值,可以用.group方法
- re.search 匹配包含,全局匹配,找到第一个符合的值返回
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
re.compile(pattern, flags=0)
Compile a regular expression pattern into a regular expression object, which can be used for matching using its match(), search() and other methods, described below.
The sequence
prog = re.compile(pattern)result = prog.match(string)
is equivalent to
result = re.match(pattern, string)
but using re.compile() and saving the resulting regular expression object for reuse is more efficient when the expression will be used several times in a single program.
re.match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
- pattern 正则表达式
- string 要匹配的字符串
- flags 标志位,用于控制正则表达式的匹配方式
import reobj = re.match('\d+', '123uuasf')if obj: print obj.group() Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为
- S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
- X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*")
re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
import reobj = re.search('\d+', 'u123uu888asf')if obj: print obj.group() re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import reobj = re.findall('\d+', 'fa123uu888asf')print obj re.sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
re.sub('[a-z]+','sb','武配齐是abc123',)re.sub('\d+','|', 'alex22wupeiqi33oldboy55',count=2)'alex|wupeiqi|oldboy55' 相比于str.replace功能更加强大
re.split(pattern, string, maxsplit=0, flags=0)
>>>s='9-2*5/3+7/3*99/4*2998+10*568/14'>>>re.split('[\*\-\/\+]',s)['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14']>>> re.split('[\*\-\/\+]',s,3)['9', '2', '5', '3+7/3*99/4*2998+10*568/14'] ['9', '2', '5', '3+7/3*99/4*2998+10*568/14']
re.fullmatch(pattern, string, flags=0)
整个字符串匹配成功就返回re object, 否则返回None
re.fullmatch('\w+@\w+\.(com|cn|edu)',"alex@oldboyedu.cn")